











 SDXL, 2048x3072. In the depths of a mystical forest, a robotic owl with night vision lenses for eyes watches over the nocturnal creatures.
SDXL, 2048x3072. In the depths of a mystical forest, a robotic owl with night vision lenses for eyes watches over the nocturnal creatures.
 SDXL, 2048x4096. Autumn season, a serene mountain lake lies beside a mountain. The leaves are yellow, the blue sky with fluffy clouds adds to the tranquility of the landscape.
SDXL, 2048x4096. Autumn season, a serene mountain lake lies beside a mountain. The leaves are yellow, the blue sky with fluffy clouds adds to the tranquility of the landscape.
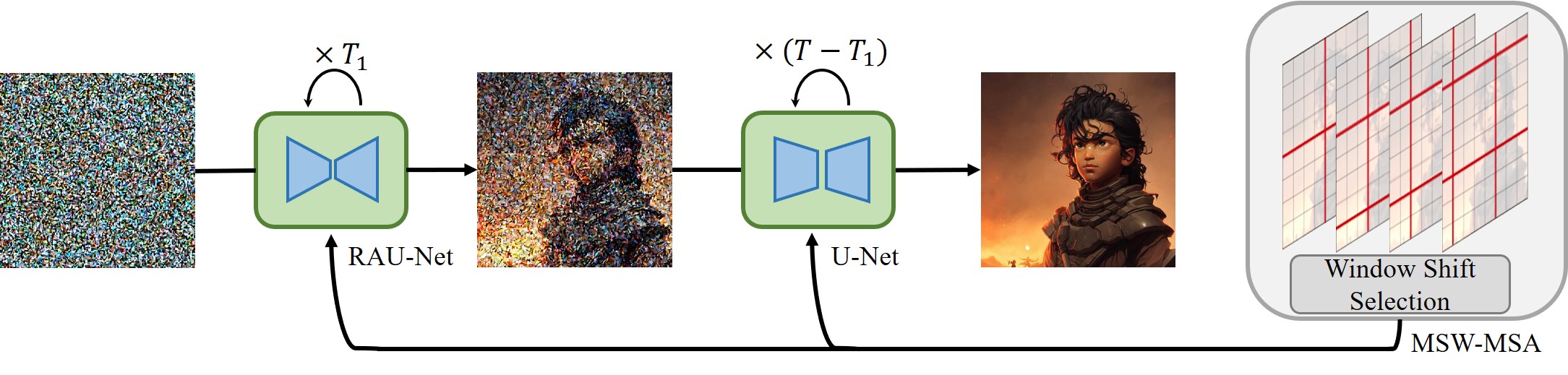
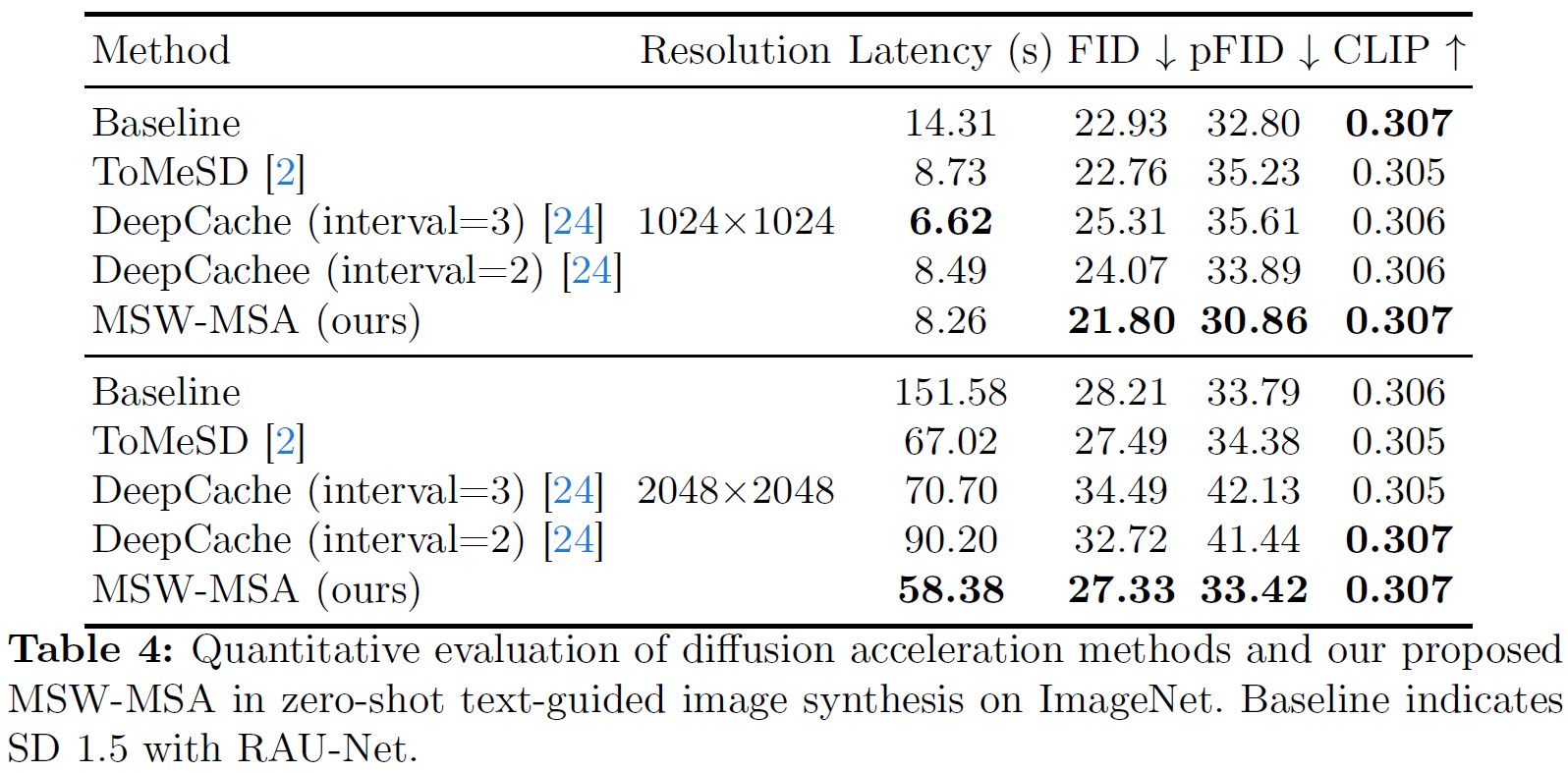
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net~(RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention(MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096×4096 at 1.5-6× the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
 2048x2048. An Astronaut in space playing an electric guitar, stylistic, cinematic, earth visible in the background.
2048x2048. An Astronaut in space playing an electric guitar, stylistic, cinematic, earth visible in the background.
 2048x2048. Girl with pink hair, vaporwave style, retro aesthetic, cyberpunk, vibrant, neon colors, vintage 80s and 90s style, highly detailed.
2048x2048. Girl with pink hair, vaporwave style, retro aesthetic, cyberpunk, vibrant, neon colors, vintage 80s and 90s style, highly detailed.
 2048x3072. Roger rabbit as a real person, photorealistic, cinematic.
2048x3072. Roger rabbit as a real person, photorealistic, cinematic.
 2048x4096. An otherworldly forest with bioluminescent trees, their neon blue leaves casting an ethereal glow on the path below, and curious creatures with gentle eyes peering from behind the glowing trunks.
2048x4096. An otherworldly forest with bioluminescent trees, their neon blue leaves casting an ethereal glow on the path below, and curious creatures with gentle eyes peering from behind the glowing trunks.
 4096x4096. An adorable happy brown border collie sitting on a bed, high detail.
4096x4096. An adorable happy brown border collie sitting on a bed, high detail.
 4096x4096. Standing tall amidst the ruins, a stone golem awakens, vines and flowers sprouting from the crevices in its body.
4096x4096. Standing tall amidst the ruins, a stone golem awakens, vines and flowers sprouting from the crevices in its body.
 2048x2048 image generation with ControlNet. We can generate better images with faster speed.
2048x2048 image generation with ControlNet. We can generate better images with faster speed.
 2048x2048 image generation on inpainting task. We can generate better images with faster speed.
2048x2048 image generation on inpainting task. We can generate better images with faster speed.
@inproceedings{zhang2025hidiffusion,
title={HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models},
author={Zhang, Shen and Chen, Zhaowei and Zhao, Zhenyu and Chen, Yuhao and Tang, Yao and Liang, Jiajun},
booktitle={European Conference on Computer Vision},
pages={145--161},
year={2025},
organization={Springer}
}